![[AWS Glue]S3とDynamoDBから取得したデータを結合(Join)するジョブを作ってみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/aws-glue.png)
[AWS Glue]S3とDynamoDBから取得したデータを結合(Join)するジョブを作ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
AWSのETLサービスであるAWS Glueでは、Amazon S3、Amazon Redshift、Amazon DynamoDBなど様々なサービスにデータソース/ターゲットとして接続することができます。
今回は、AWS GlueでS3とDynamoDBから取得したデータを結合(Join)するジョブを作ってみました。
作ってみた
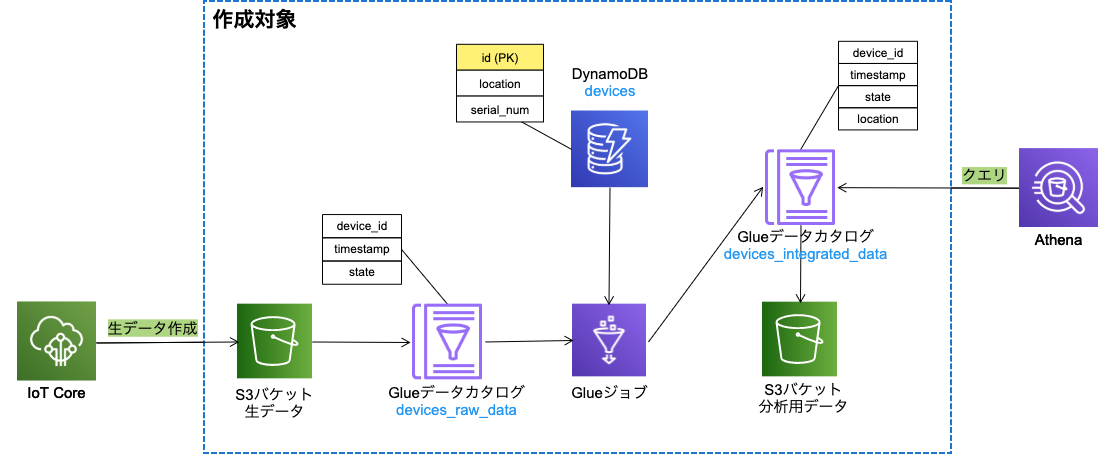
以下のような構成の、デバイスからIoT Core経由で送信される生データ(devices_raw_data)と、DynamoDBにて定義したデバイステーブル(devices)のデータを、GlueジョブでデバイスIDを元にして結合して分析用データ(devices_integrated_data)を作成する仕組みを作成します。
CloudFormationテンプレート
前述の構成の作成対象となるリソースをCloudFormationテンプレートで定義します。
※本来なら、デバイステーブル(DevicesDynamoDBTable)と生データのバケット(DevicesRawDataBucket)のリソースは別スタックで作成したい所ですが、今回は簡単のため同じスタックで作成してしまいます。
AWSTemplateFormatVersion: '2010-09-09'
Resources:
DevicesDynamoDBTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: devices
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
BillingMode: PAY_PER_REQUEST
DevicesRawDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-raw-data-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-data-analytics-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: devices_data_analystics
RawDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_raw_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesRawDataBucket}/raw-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
IntegratedDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_integrated_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
- Name: location
Type: string
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesDataAnalyticsBucket}/integrated-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state, location"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
ExecuteETLJobRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Principal:
Service:
- glue.amazonaws.com
Action:
- sts:AssumeRole
Policies:
- PolicyName: devices-data-etl-glue-job-policy
PolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Action:
- glue:StartJobRun
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:job/devices-data-etl
-
Effect: Allow
Action:
- glue:GetPartition
- glue:GetPartitions
- glue:GetTable
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:catalog
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:database/${DevicesDataAnalyticsGlueDatabase}
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesDataAnalyticsGlueDatabase}/${RawDataGlueTable}
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesDataAnalyticsGlueDatabase}/${IntegratedDataGlueTable}
-
Effect: Allow
Action:
- glue:GetJobBookmark
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesDataAnalyticsGlueDatabase}/${RawDataGlueTable}
-
Effect: Allow
Action:
- s3:ListBucket
- s3:GetBucketLocation
Resource:
- arn:aws:s3:::*
-
Effect: Allow
Action:
- logs:CreateLogStream
- logs:CreateLogGroup
- logs:PutLogEvents
Resource: !Sub arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws-glue/jobs/*
-
Effect: Allow
Action:
- s3:GetObject
Resource:
- !Sub arn:aws:s3:::${DevicesRawDataBucket}/raw-data/*
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/glue-job-script/devices-data-etl.py
-
Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/glue-job-temp-dir/*
-
Effect: Allow
Action:
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/integrated-data/*
-
Effect: Allow
Action:
- dynamodb:ListTables
Resource:
- !Sub arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/*
-
Effect: Allow
Action:
- dynamodb:DescribeTable
- dynamodb:Scan
Resource:
- !Sub arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/${DevicesDynamoDBTable}
DevicesDataETLGlueJob:
Type: AWS::Glue::Job
Properties:
Name: devices-data-etl
Command:
Name: glueetl
PythonVersion: 3
ScriptLocation: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-script/devices-data-etl.py
DefaultArguments:
--job-language: python
--job-bookmark-option: job-bookmark-enable
--TempDir: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-temp-dir
--GLUE_DATABASE_NAME: !Sub ${DevicesDataAnalyticsGlueDatabase}
--SRC_GLUE_TABLE_NAME: !Sub ${RawDataGlueTable}
--DEST_GLUE_TABLE_NAME: !Sub ${IntegratedDataGlueTable}
--DEVICES_TABLE_NAME: !Sub ${DevicesDynamoDBTable}
GlueVersion: 2.0
ExecutionProperty:
MaxConcurrentRuns: 1
MaxRetries: 0
Role: !Ref ExecuteETLJobRole
Glueジョブスクリプト
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
args = getResolvedOptions(
sys.argv,
[
'JOB_NAME',
'GLUE_DATABASE_NAME',
'SRC_GLUE_TABLE_NAME',
'DEST_GLUE_TABLE_NAME',
'DEVICES_TABLE_NAME'
]
)
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
df = glueContext.create_dynamic_frame.from_catalog(
database = args['GLUE_DATABASE_NAME'],
table_name = args['SRC_GLUE_TABLE_NAME'],
transformation_ctx = 'datasource'
).toDF()
df.show()
devices_df = glueContext.create_dynamic_frame_from_options(
'dynamodb',
connection_options={
'dynamodb.input.tableName': args['DEVICES_TABLE_NAME']
}
).toDF()
devices_df.show()
df = df.join(devices_df,
df.device_id == devices_df.id,
'left'
)
df.show()
df = df.select(
'device_id',
'timestamp',
'state',
'location'
)
df.show()
dyf = DynamicFrame.fromDF(df,
glueContext,
'integrated_data'
)
glueContext.write_dynamic_frame.from_catalog(
frame = dyf,
database = args['GLUE_DATABASE_NAME'],
table_name = args['DEST_GLUE_TABLE_NAME'],
transformation_ctx = 'datasink'
)
job.commit()
スクリプトの解説
※ここでのshow()メソッドの表示結果は、後述の動作確認で使用した生データの場合の結果です。
生データをデータカタログを介してS3バケットから取得しています。
df = glueContext.create_dynamic_frame.from_catalog( database = args['GLUE_DATABASE_NAME'], table_name = args['SRC_GLUE_TABLE_NAME'], transformation_ctx = 'datasource' ).toDF()
取得した生データのDataFrameは次のようになります。
>> df.show() +---------+-------------+-----+ |device_id| timestamp|state| +---------+-------------+-----+ | 7d4215d0|1608976046746| true| | e36b7dfa|1608976059078| true| | 7d4215d0|1608976150001|false| | 20d43750|1609493741528| true| +---------+-------------+-----+
デバイステーブルをDynamoDBから取得しています。
devices_df = glueContext.create_dynamic_frame_from_options(
'dynamodb',
connection_options={
'dynamodb.input.tableName': args['DEVICES_TABLE_NAME']
}
).toDF()
- create_dynamic_frame_from_options | GlueContext Class - AWS Glue
- "connectionType": "dynamodb" | Connection Types and Options for ETL in AWS Glue - AWS Glue
取得したデバイステーブルのDataFrameは次のようになります。
>> devices_df.show() +--------+--------+------------+ |location| id| serial_num| +--------+--------+------------+ | A-2|a263163c|4E54533A3403| | A-1|7d4215d0|4E54533A3403| | B-1|e36b7dfa|ABEDF36C521B| +--------+--------+------------+
生データとデバイステーブルをそれぞれのデバイスIDのカラムdevice_idとidを元に結合します。
df = df.join(devices_df, df.device_id == devices_df.id, 'left' )
結合後のDataFrameは次のようになります。20d43750は対応するデバイスIDのデータがデバイステーブルに無いため、location、id、serial_num列がnullとなっています。
>> df.show() +---------+-------------+-----+--------+--------+------------+ |device_id| timestamp|state|location| id| serial_num| +---------+-------------+-----+--------+--------+------------+ | 20d43750|1609493741528| true| null| null| null| | e36b7dfa|1608976059078| true| B-1|e36b7dfa|ABEDF36C521B| | 7d4215d0|1608976046746| true| A-1|7d4215d0|4E54533A3403| | 7d4215d0|1608976150001|false| A-1|7d4215d0|4E54533A3403| +---------+-------------+-----+--------+--------+------------+
分析用データとして必要なカラムのみをSelectします。
df = df.select( 'device_id', 'timestamp', 'state', 'location' )
Select後のDataFrameは次のようになります。
>> df.show() +---------+-------------+-----+--------+ |device_id| timestamp|state|location| +---------+-------------+-----+--------+ | 20d43750|1609493741528| true| null| | e36b7dfa|1608976059078| true| B-1| | 7d4215d0|1608976046746| true| A-1| | 7d4215d0|1608976150001|false| A-1| +---------+-------------+-----+--------+
デプロイ
CloudFormationスタックをデプロイします。
% aws cloudformation deploy \ --template-file template.yaml \ --stack-name devices-data-analytics-stack \ --capabilities CAPABILITY_NAMED_IAM \ --no-fail-on-empty-changeset
GlueジョブのスクリプトをS3バケットにアップロードします。
% ACCOUNT_ID=<Account ID>
% AWS_REGION=<AWS Region>
% aws s3 cp devices-data-etl.py s3://devices-data-analytics-${ACCOUNT_ID}-${AWS_REGION}/glue-job-script/devices-data-etl.py
動作確認
生データをS3バケットにアップロードします。
{"device_id": "7d4215d0", "timestamp": 1608976046746, "state": true}
{"device_id": "e36b7dfa", "timestamp": 1608976059078, "state": true}
{"device_id": "7d4215d0", "timestamp": 1608976150001, "state": false}
{"device_id": "20d43750", "timestamp": 1609493741528, "state": true}
% aws s3 cp raw-data.json s3://devices-raw-data-${ACCOUNT_ID}-${AWS_REGION}/raw-data/raw-data.json
DynamoDBテーブルにデバイスマスターデータを登録します。
% aws dynamodb put-item --table-name devices \
--item '{"id": {"S": "7d4215d0"}, "location": {"S": "A-1"}, "serial_num": {"S": "4E54533A3403"}}'
% aws dynamodb put-item --table-name devices \
--item '{"id": {"S": "e36b7dfa"}, "location": {"S": "B-1"}, "serial_num": {"S": "ABEDF36C521B"}}'
% aws dynamodb put-item --table-name devices \
--item '{"id": {"S": "a263163c"}, "location": {"S": "A-2"}, "serial_num": {"S": "4E54533A3403"}}'
ジョブを実行します。
% aws glue start-job-run --job-name devices-data-etl
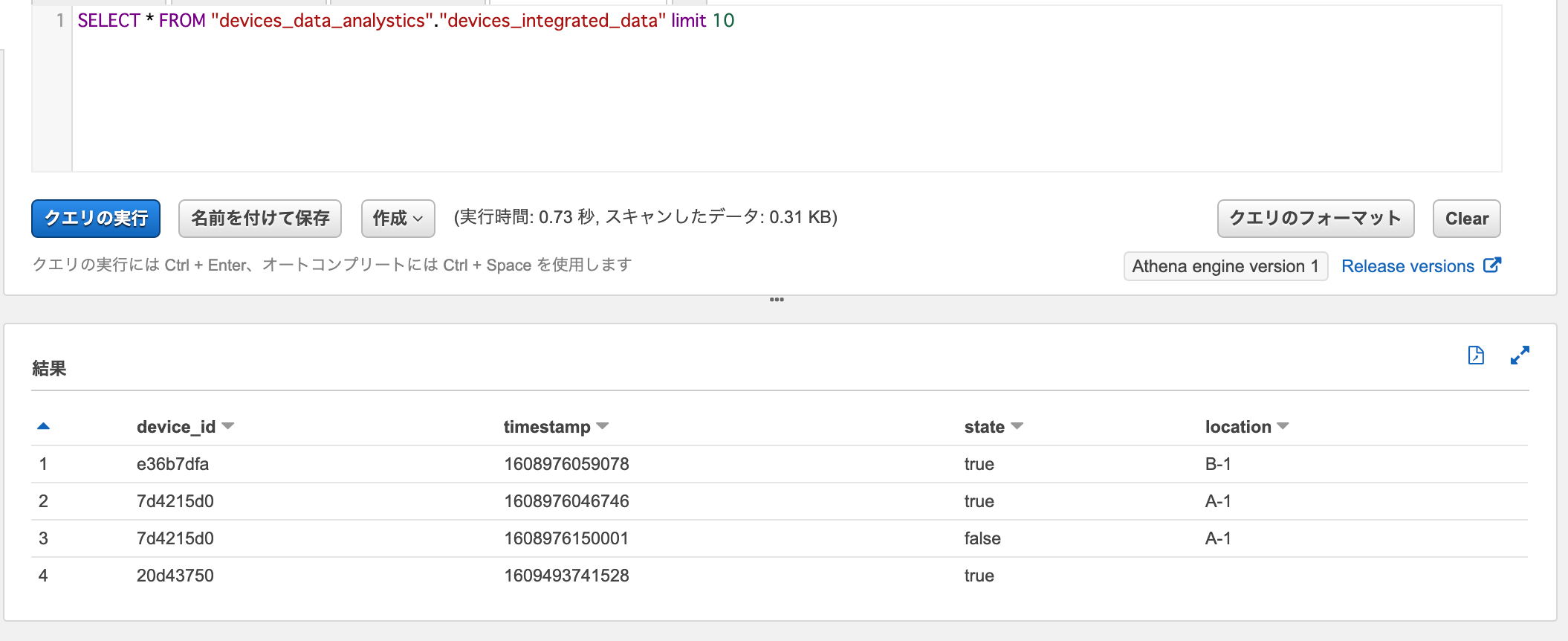
SELECT * FROM "devices_data_analystics"."devices_integrated_data" limit 10
Athenaでdevices_integrated_dataに対してSelectクエリを実行すると、生データとデバイステーブルが結合されたデータが取得できました。
おわりに
AWS GlueでS3とDynamoDBから取得したデータを結合(Join)するジョブを作ってみました。
IoTデバイスから送信されるデータは最低限の情報しか持たせない場合が多いと思うので、IoTデータの分析をしたい場合に今回のような結合処理が役に立つかと思います。
参考
以上








